| α | -6 | -4 | -2 | 0 | 2 | 4 | 6 |
| |
70% | 79% | 89% | 100 % | 112% | 126% | 141% |
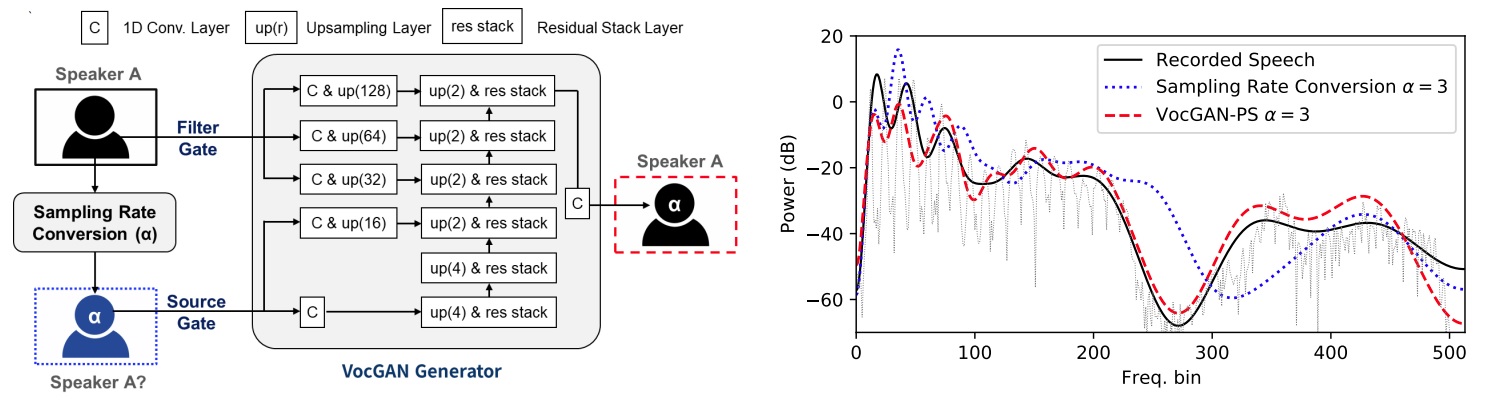
| Sample 1 Output samples by the Source and Filter gates. | |||
| Input Speech | Source Gate | (Vocal Tract) Filter Gate *Warning |
|
| Korean (NCFemale) | |||
| English (LJSpeech) | |||
| Sample 2 VocGAN-PS samples / Timbre-preserving or not | |||||||
| α | -3 | -2 | -1 | Input (KOR) | +1 | +2 | +3 |
| Sampling Rate Conversion |
|||||||
| VocGAN-PS | |||||||
| α | -3 | -2 | -1 | Input (ENG) | 1 | 2 | 3 |
| Sampling Rate Conversion |
|||||||
| VocGAN-PS |
| Sample 3 Timbre-Preserving PS Alogirithms : (1) TD-PSOLA-PS, (2) WORLD-PS and (3) VocGAN-PS (Proposed) |
|||||||
| α | -3 | -2 | -1 | Input (KOR) | +1 | +2 | +3 |
| (1) TD-PSOLA-PS | |||||||
| (2) WORLD-PS | |||||||
| (3) VocGAN-PS | |||||||
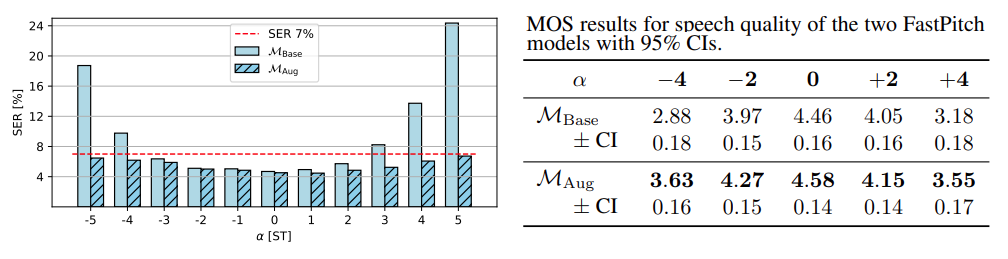
| Sample | 1 | 2 | 3 | 4 | 5 |
| α | -4 | -4 | +4 | +4 | +4 |
| Baseline Model w/o Pitch-Augment. |
|||||
| Augment. Model Proposed |
| Sample | 1 | 2 | 3 | 4 | 5 |
| α | +2 | +2 | +2 | +2 | +2 |
| Baseline Model w/o Pitch-Augment. |
|||||
| Augment. Model Proposed |
|||||
| α | 0 | 0 | 0 | 0 | 0 |
| Baseline Model w/o Pitch-Augment. |
|||||
| Augment. Model Proposed |
|||||
| α | -2 | -2 | -2 | -2 | -2 |
| Baseline Model w/o Pitch-Augment. |
|||||
| Augment. Model Proposed |
| Sample | 1 | 2 | 3 | 4 | 5 |
| α | -6 | +6 | +6 | -6 | -6 |
| Baseline Model w/o Pitch-Augment. |
|||||
| Augment. Model Proposed |
| Sample | 1 | 2 | 3 | 4 | 5 |
| α | +3 | +3 | +3 | +3 | +3 |
| Baseline Model w/o Pitch-Augment. |
|||||
| Augment. Model Proposed |
|||||
| α | 0 | 0 | 0 | 0 | 0 |
| Baseline Model w/o Pitch-Augment. |
|||||
| Augment. Model Proposed |
|||||
| α | -3 | -3 | -3 | -3 | -3 |
| Baseline Model w/o Pitch-Augment. |
|||||
| Augment. Model Proposed |