A NEURAL TEXT-TO-SPEECH MODEL UTILIZING BROADCAST DATA MIXED WITH BACKGROUND MUSIC
Hanbin Bae, Jae-Sung Bae, Young-Sun Joo, et al
bhb0722@ncsoft.com
Abstract
Recently, it has become easier to obtain speech data from various media such as the internet
or YouTube, but directly utilizing them to train a neural text-to-speech (TTS) model is difficult.
The proportion of clean speech is insufficient and the remainder includes background music.
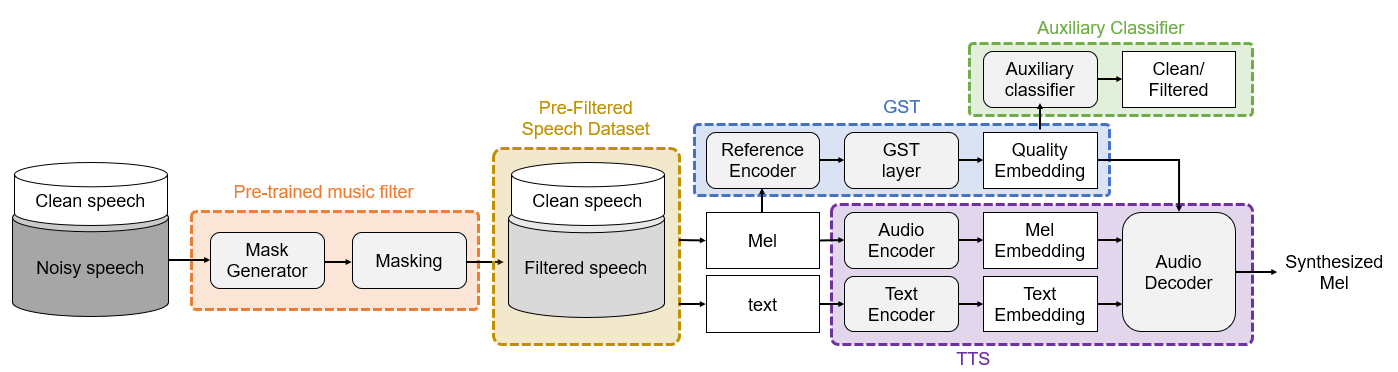
Even with the global style token (GST). Therefore, we propose the following method to successfully
train an end-to-end TTS model with limited broadcast data. First, the background music is removed
from the speech by introducing a music filter. Second, the GST-TTS model with an auxiliary quality
classifier is trained with the filtered speech and a small amount of clean speech. In particular, the
quality classifier makes the embedding vector of the GST layer focus on representing the speech
quality (filtered or clean) of the input speech. The experimental results verified that the proposed
method synthesized much more high-quality speech than conventional methods.
To train a speaker-independent music filter, we use the KsponSpeech dataset.
dataset, which comprises approximatly 1,000 h of spontaneous speech samples recorded by 2,000 people talking about various topics, sampled at 16 kHz.
1. Male
1. TTS: the DC-TTS [2] model usedconducted in the pre-liminary experiments.
2. GST: the GST-TTS model where the quality embeddingfrom the GST layers was concatenated into the encoderstate of DC-TTS.
3. GST+MF: the GST-TTS model trained with filteredspeech obtained from the pre-trained music filter.
4. GST+MF+Aux.: the GST+MF model with an auxiliaryclassifier.