| Sentence: 진짜 귀찮으면 번갈아서 나오는데 내가 모르는 거 아닐까? (Pronunciation): jinjja gwichanheumyeon beongaraseo naoneunde naega moreuneun geo anilkka? |
||
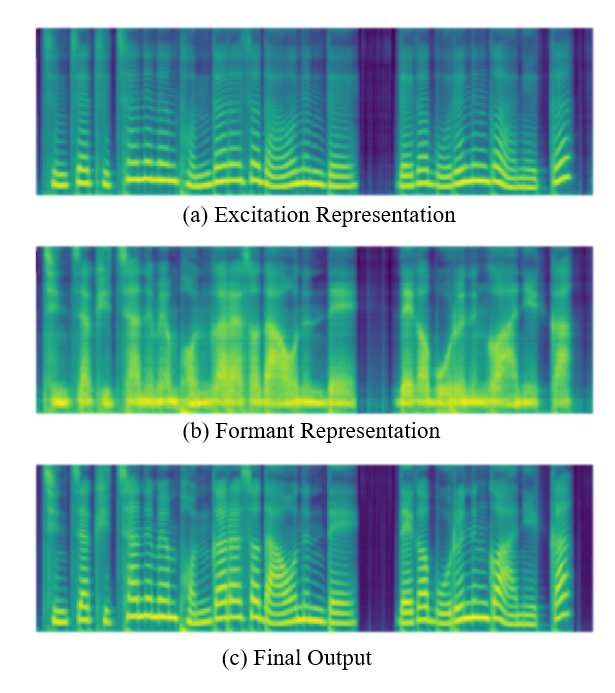
| Excitation Representation | Formant Representation | Final Output |
| λ | -8 | -6 | -4 | 0 | +4 | +6 | +8 |
| |
63% | 71% | 79% | 100 % | 126% | 141% | 159% |
| Sentence: 나는 몇 달째 계속 못 들고 있는데 넌 어떻게 들었어? (Pronunciation): naneun myeot daljjae gyesok mot deulgo issneunde neon eotteohge deureosseo? |
|||||||
| λ | -8 | -6 | -4 | Female (KOR) | +4 | +6 | +8 |
| FastPitch (Baseline) |
|||||||
| FastPitchFormant (proposed) |
|||||||
| Excitation Representation from FastPitchFormant (proposed) |
|||||||
| Formant Representation from FastPitchFormant (proposed) |
|||||||
| Sentence: 그리고 내일은 조금 무더울 거예요. (Pronunciation): geurigo naeireun jogeum mudeoul geoyeyo. |
|||||||
| λ | -8 | -6 | -4 | Male (KOR) | +4 | +6 | +8 |
| FastPitch (Baseline) |
|||||||
| FastPitchFormant (proposed) |
|||||||
| Excitation Representation from FastPitchFormant (proposed) |
|||||||
| Formant Representation from FastPitchFormant (proposed) |
|||||||
| Sentence: Warm and cold baths, or commodious bathing tubs, |
|||||||
| λ | -8 | -6 | -4 | LJSpeech (ENG) | +4 | +6 | +8 |
| FastPitchFormant (proposed) |
|||||||
| Excitation Representation from FastPitchFormant (proposed) |
|||||||
| Formant Representation from FastPitchFormant (proposed) |
|||||||